我們在 T 值估計有介紹過 clock 週期 $t_{period}$ 的重要性。不過在一般的設計中,我們還是會優先考量總週期數 $n$。當我們用週期數來考量時, AT 值背後的意義就是一個演算法的總運算量。
AT 值與演算法運算量
假設現在要做一個 16 個數值的總和的演算法。你的設計方式一定是利用加法器實作,可以是一個加法做 16 個周期、四個加法做 4 個週期等等。如果再不考量 clock 週期的情況下,這幾種做法的 AT 值都會非常相近。
但是如果你發現了資料有一個固定的特性,假設是前後對稱 (1 = 16, 2 = 15, …, 7 = 8),這樣實際狀況只需要 8 個運算,你的 AT 值就可以少一半。
在這樣簡單的例子中,我們可以看到 AT 值的設計中,*演算法的運算量將會是一個關鍵。這也是我們在學軟體的演算法時常學到的。因此,在優化運算量上面各位應該都非常的熟悉。例如,我們常常可以想到那些運算是多餘的,可以跳過。
然而,並不是所有的演算法都是單一硬體組成。常見的運算有 +、-、x、/ 等。那我們該怎麼進一步優化呢?
AT 值的進一步優化:硬體共用
架設我們現在有一個硬體要設計,且可分為 A 和 B 兩個演算法。參考下圖 A 為藍色、B 為綠色,橫軸是時間、縱軸代表運算單元。塗色與否代表該硬體在該時間單位是否有被使用。
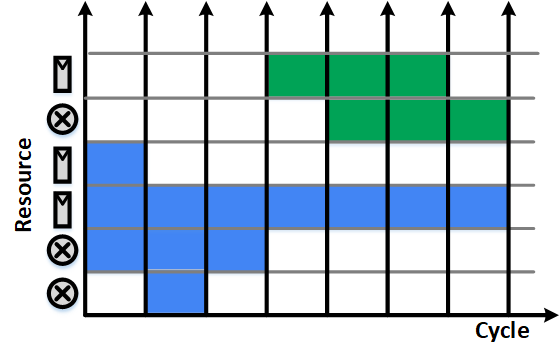
在前一部份,我們應該都設計出很低運算量的 A 和 B 演算法了。但是由於我們在寫 verilog 時,時常是把不同演算法分成不同的 module 來寫。這就會導致一個問題,A 和 B 演算法不會共用同一樣的硬體單元。
假設現在 A 演算法已經運算完成,也有剩餘的硬體可以使用,我們應該就要想辦法去把 B 演算法中的硬體替換成 A 的硬體。常見的是,A 中的乘法器在某個時間點後已經不需要運算,我們就可以用 mux 切換他來運算 B 演算法。
更進階的是共用 register,這也是最常見可以優化的部分。我們時常會需要同時存很多資料,但一小段時間後很多都會 idle。這時候,我們就可以利用 mux 來切換,把這些 idle 的 register 拿來存 B 演算法需要的數值。要注意的是,我們在 A 值估計提過 register 和加法器的面積是差不多大的。因此,如果要優化面積,register 的共用會是一個關鍵。
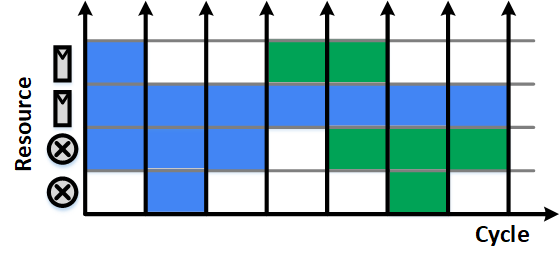
小節
對於特定 T 下,最優化 AT,我推薦的作法很簡單:(1) 先最小化運算量,能省的運算就省 (2) 進一步的共用 idle 的硬體來降低面積。